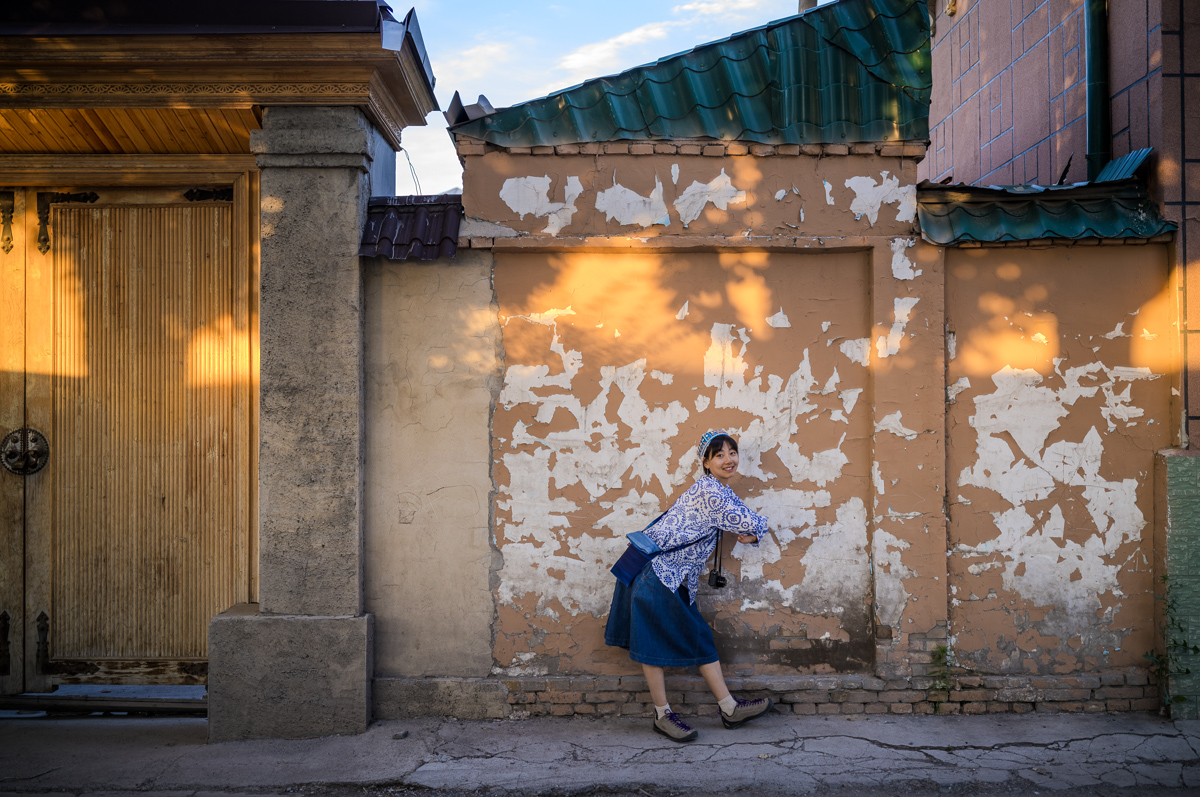debug for wordpress 6.11
Dreamility
Frish's Blog
-
2025 年 5 月第二次去了新疆,目的地是伊犁地区。一拖半年,最近终于把视频剪完了:
年底连续打游戏,拇指腱鞘炎了,几乎握不了鼠标。于是决定放过自己,放任一些视频中的 bug,直接导出了(所以一些镜头的颜色可能怪怪的)。
换了一个只有 44g 的 LOGI Superlight 2c 鼠标写完了本篇博客救我狗爪。 😭
我自己很喜欢的是这次的小海报,拍摄于喀拉峻大草原。

出发前正好 DJI Mavic 4 Pro 发布,纠结了好几天这个重量。事实证明真的没白带,有很多我喜欢的照片都是用无人机拍摄,主要是方便拍合影。而 M4P 的长焦很容易拍摄出 Cine Style。
喜欢春夏的新疆,非常符合我自己的生物节律:早上九十点钟一天开始,到晚上十点钟太阳高挂,感觉一天很长。这几张照片是晚上 10 点之后,在赛里木湖等待日落。真正天黑要等到晚上 11 点半左右。
早上的赛里木湖,宁静而美好。是个阴天,没有明媚灿烂,多了很多温和轻叹。
下雨天,遇到彩虹 🌈。
新疆是一个非常吃天气的地方,阴天的赛里木湖,和晴天的赛里木湖,其实不是一个赛里木湖。☀️
那拉提大草原,晚上(但仍然太阳高照)在草地上坐一会儿晒太阳,非常舒服。
喀拉峻草原,伊犁之行最舒服的一段徒步。
那拉提草原外的小镇,午夜 12点半
伊宁,一个很多蓝色,热热闹闹,人们在自家门口树上摘果子吃的城市。
传说中的独库公路,名不虚传。河流溪谷、雪山青草。找个小溪边,带上小零食,放下露营椅。
独山子大峡谷,非常壮阔的地貌。⛰️
回到乌鲁木齐。乌鲁木齐是我非常喜欢的城市,不限量的阳光,丰富的人群画像。以及餐厅门口就这样随时起舞的简单缓慢。
最后一张,飞机上拍的乌鲁木齐附近。一边是农田,一边是一望无际的戈壁、峡谷与沙漠。生机盎然、优美肥厚与飞沙走石、严酷荒凉之间勾连交错,杂糅混合,也许就是新疆最有魅力的地方。

这是我和 Mono 的第 5 个旅行 Vlog,2025 年另外两次旅行的大量素材还躺在硬盘里,希望 2026 年能把他们剪完 >_<。2025 终于过去啦,新年快乐呦~ 🎆
过往旅行 Vlog 系列:
伊犁漫行无评论