很久没折腾 Home Assistant 了,近期从范老师那里收到了一款很好玩的内测产品 Sleepal,可以通过 Matter 协议接入 HA,通过非接触的方式监测睡眠状态。可以在 HA 拿到入睡状态,近而实现一些原来不能实现的自动化,非常有趣,分享一下。

首先说一下 Sleepal AI Lamp
不知道中文名叫啥,睡宝?睡灯?… 睡登?😂
之前 Webto 还在范老师那搬砖的时候参与过这款产品,那时我正被睡眠问题困扰,之前听他聊起来就非常感兴趣:
- 放在床头,不需要佩戴,即可像 Apple Watch 一样跟踪睡眠。
- 睡眠分析:通过手机的数据结合 AI 给出睡眠的改善建议。(最早我记得是说基于 CBTi,这部分还没体验到。)
- 哄睡功能和无痛唤醒,具有 RGB 氛围灯和白噪音音箱。
具体的原理是通过配备的毫米波雷达点阵和热阵列传感器、声学传感器来跟踪身体数据,同时通过收集环境光、温湿度信息评估睡眠环境。

我拿到的测试版,实际用起来的感受就是睡觉不用佩带 Apple Watch,也能拿到和 Apple Watch 一样的睡眠数据了,数据也可以同步到 Apple Health。准确度上我感觉和 Apple Watch 差不多,同时会提供一些比 Apple Watch 更详细一些的维度,比如睡姿、睡眠环境分析等。我测试的重点主要是 HA 连动,更详细的功能介绍可以去看产品的众筹页面或官网。

首个可以接入 HA 的非接触入睡传感器
先加足够定语叠个甲,因为接触式的似乎有 Withings Sleep 以及个别自制方案。非接触式做到 Apple Watch 精准度的完整产品应该是头一个?
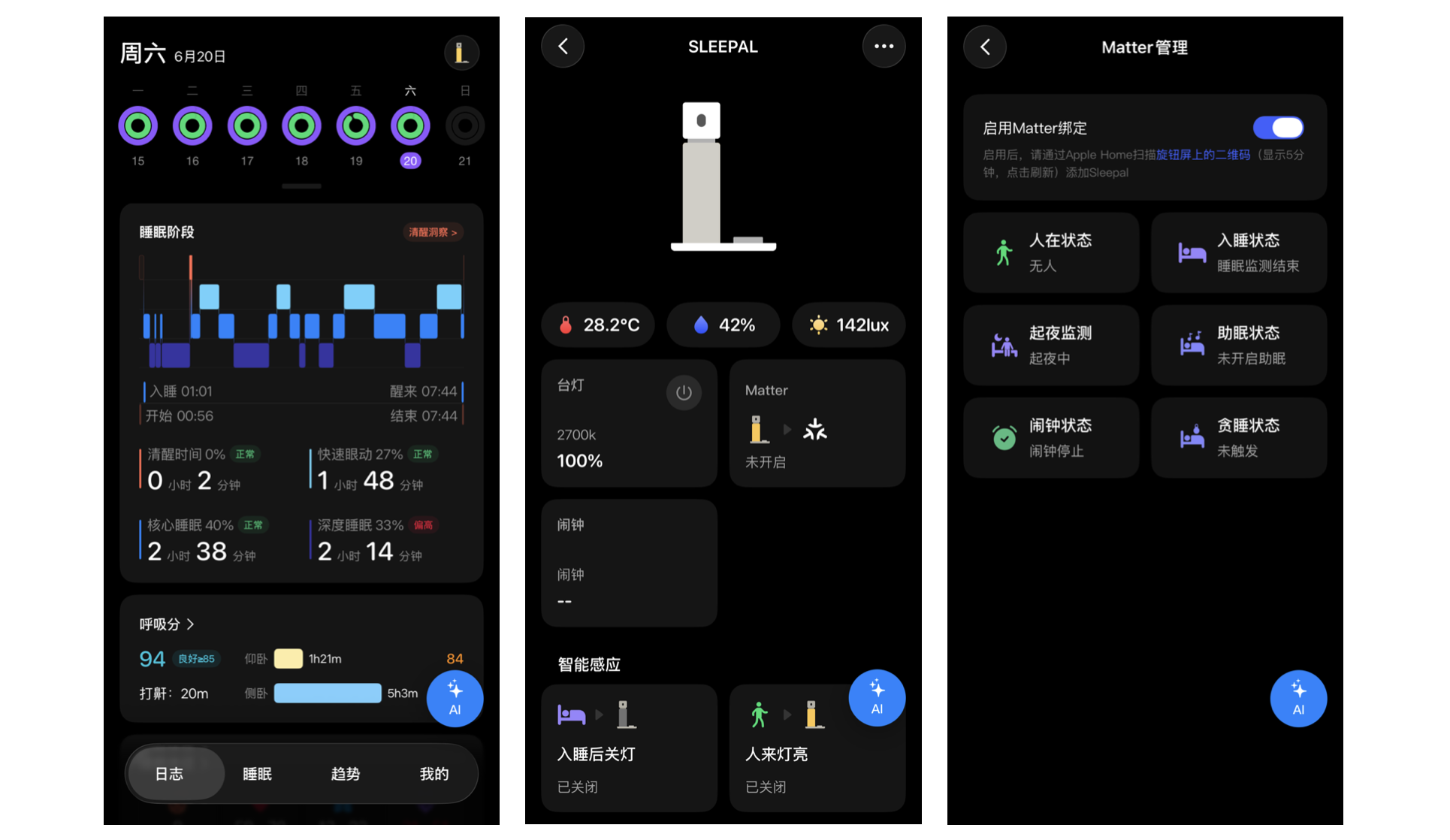
Sleepal 支持 Matter,可以通过 Matter 方式接入 HomeKit 和 Home Assistant。具体方式是通过 Sleepal App > 我的 > 我的 Sleepal > Matter ,打开配对即可开启。因为目前 Matter 功能还在内测,所以传感器还没有整理,目前可以得到有效的 HA 实体:
- 一个
light实体:控制 Sleepal 的灯光,目前支持亮度、冷暖调节,RGB 的部分还没有接入。 - 一组
binary_sensor实体:入睡状态、在床状态、起夜监测、助眠状态、闹钟和 Snooze,以及还有一些不知道作用的实体 - 一组
sensor实体:环境温度、湿度、照度
Matter 进 HomeKit 时,表现为灯光和一组人在传感器
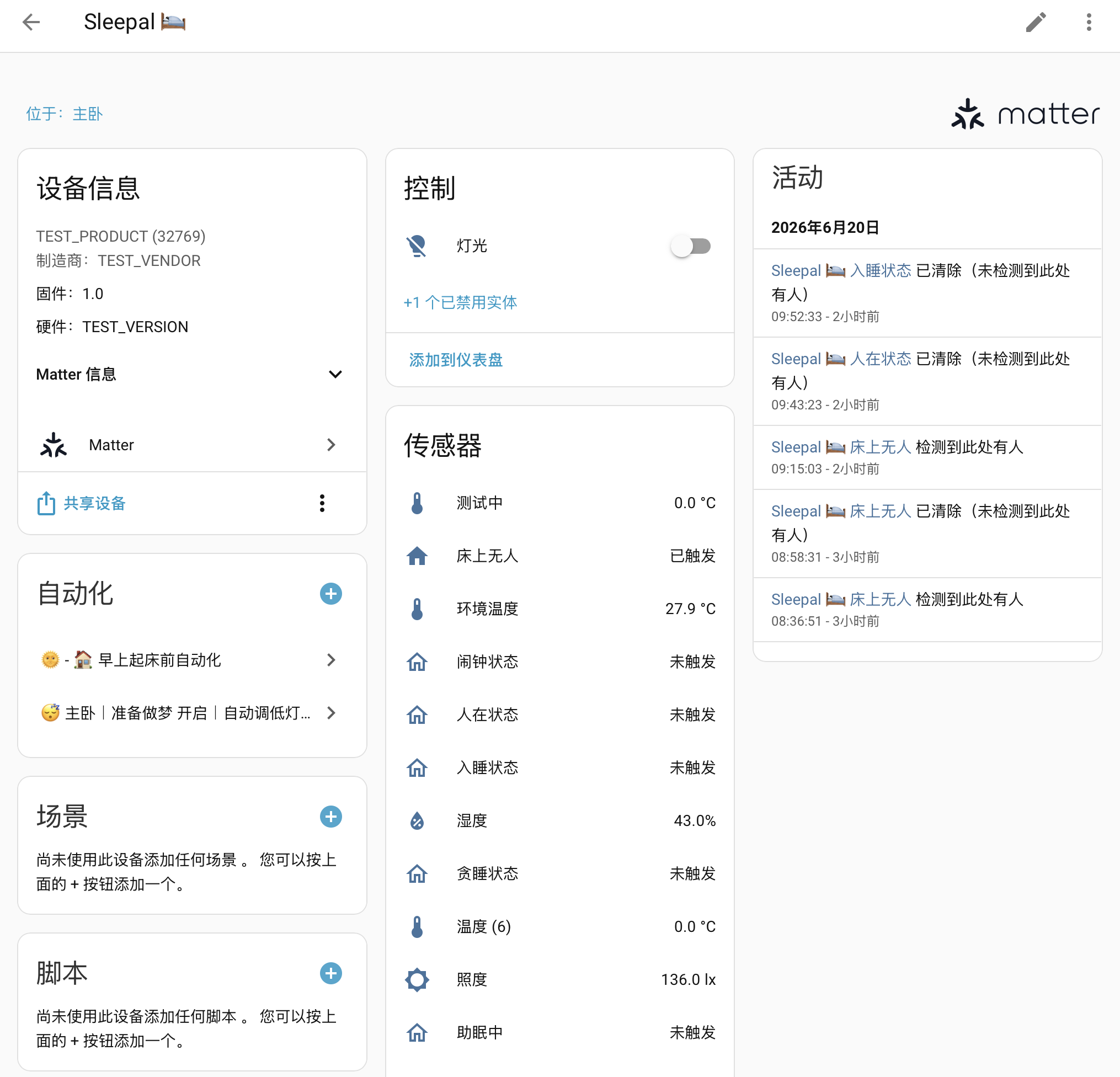
目前对我比较有用的实体就是入睡状态和在床状态。
入睡传感器,是一个非常有用的自动化 Trigger!
一天最重要的生活场景转化发生在卧室,我的卧室就有非常多的自动化,它们围绕着入睡与醒来。比如入睡前播放助眠音乐,调暗卧室灯光,开启环境家电与卧室外的监控摄像头。或者醒来时开启窗帘,调整灯光场景等。
其中一些场景可以主动触发(如语音指令或按钮),或者做基于时间触发的自动化。但一些场景就比较麻烦,比如睡着后关闭助眠音乐 – 因为你无法在睡着的时候告诉 HA 你睡着了 >_<!
之前有关人的状态就只有人在传感器与运动传感器,它们都无法分辨入睡状态,有了入睡/醒来状态,思路一下就打开了。分享几个我最近用的有趣的场景。
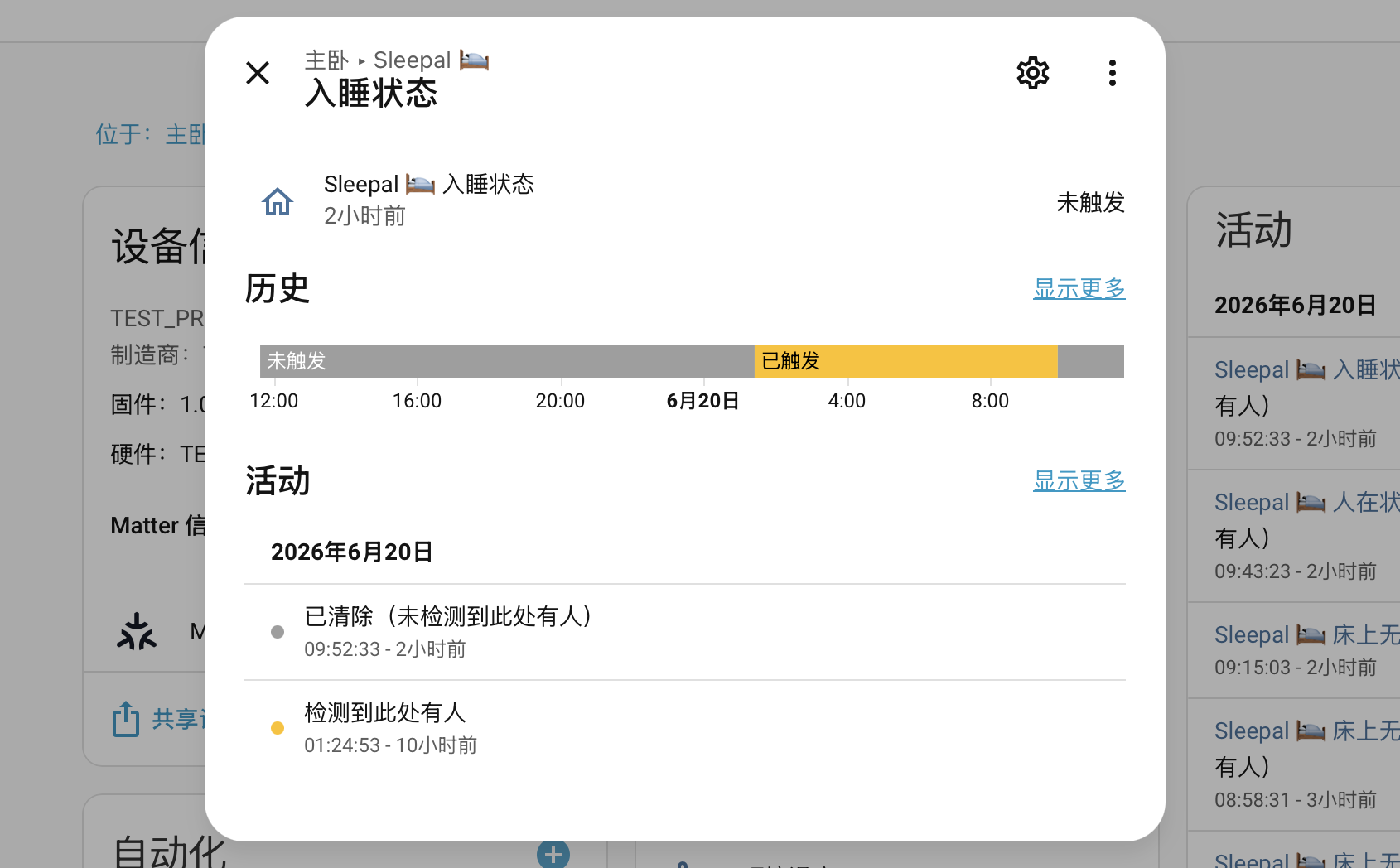
💤 睡着后,关闭 🎵助眠音乐,关闭 💡主卧灯光
之前失眠耳鸣给自己找到的哄睡办法是 HomePod 播放助眠音乐,同时主卧将灯光调到舒适的暗调。通过一个倒计时逐渐调低音量和灯光。Time Based Rule 的问题就是有时没睡着音乐停了,或者睡着了又给吵醒了。入睡传感器完美解决了这个问题。
再推荐一下我的 Nanoleaf 木纹奇光板吧!我用它模拟睡前摇曳的烛火氛围。
💤 入睡后,开启摄像头。🛏️ 起夜 或 🌞醒来时,关闭摄像头
卧室外有几个小米摄像头做出差看家。有了入睡检测后,可以在睡着后也自动开启。醒来时关闭,避免拍下衣衫不整的自己 😳。
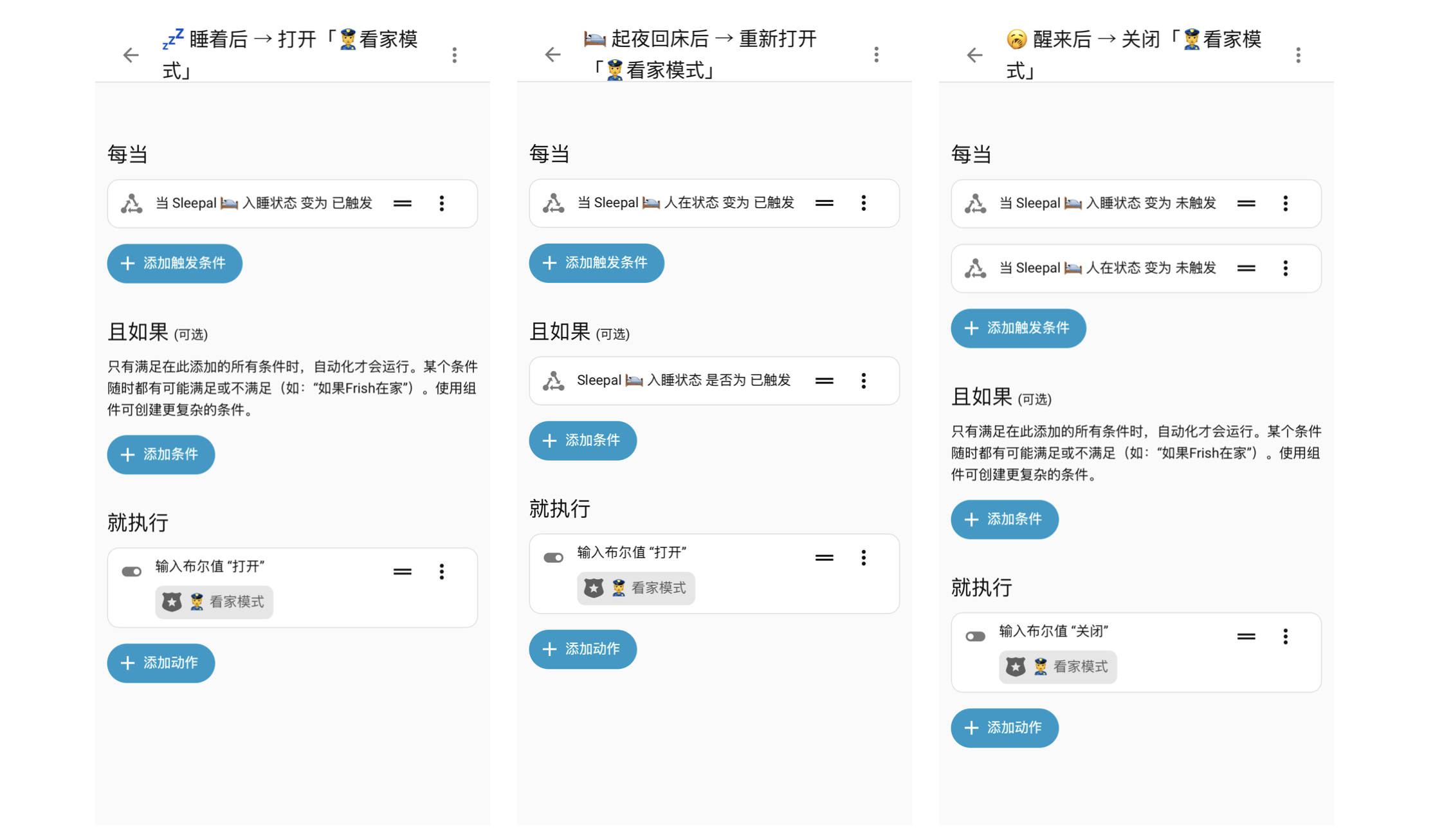
🌞 起床后,关闭环境电器,自动开灯
原来我的主卧新风、加湿器与空调都是基于定时关闭的,现在可以时间更酷的自动化。我的厨房和餐厅是我早起洗漱后第一个要去的地方,我新家了一个自动化:起床后,如果阴天的话,帮我开启餐厅的射灯。新的一天还是要有一个明亮的开始!
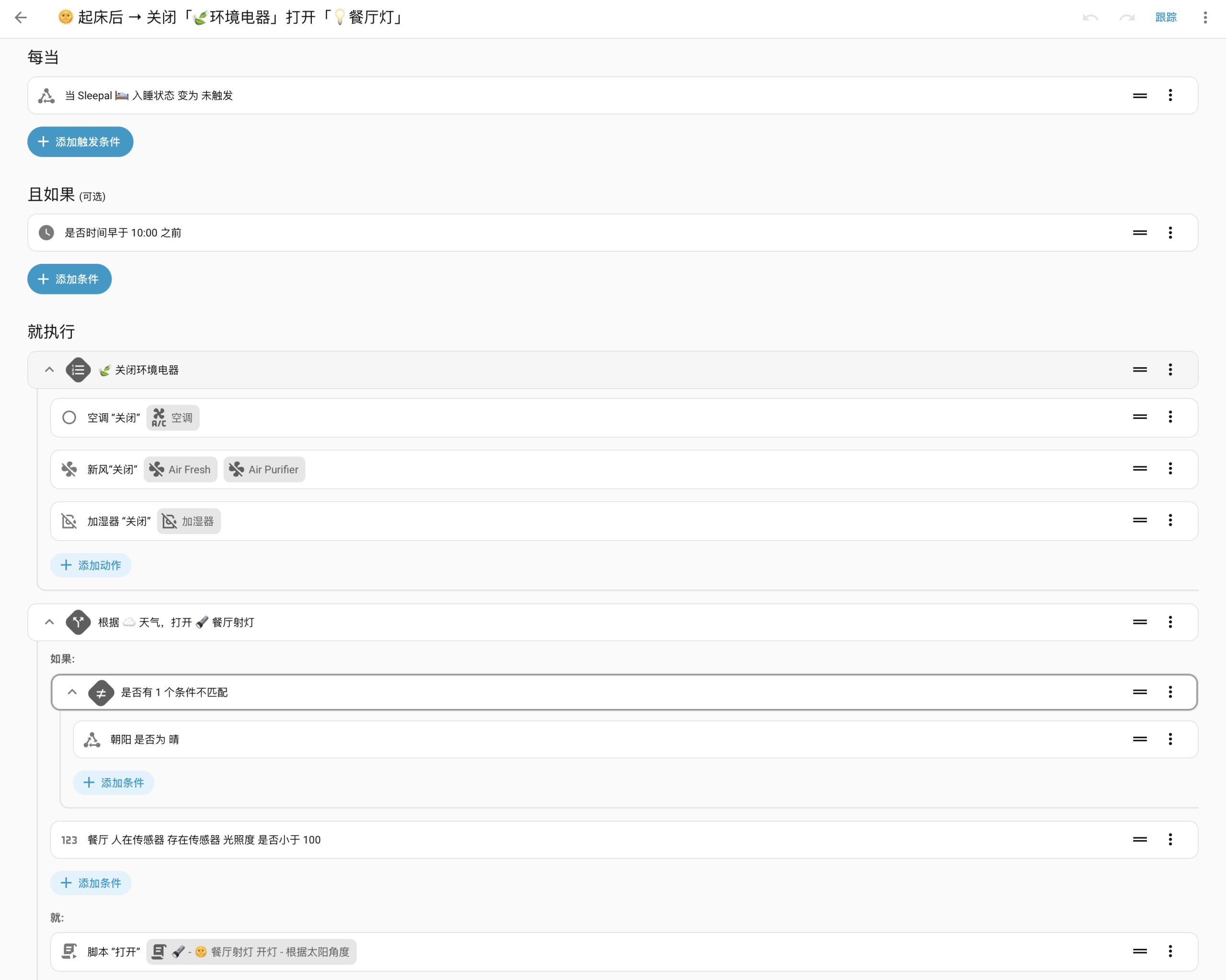
脚本说明:我餐厅四个角有 4 盏射向天花板的,我让它们根据太阳的入射角
sensor.sun_solar_azimuth来独立调整亮度,让光源模拟真实太阳光的方向,以实现更好的清晨唤醒效果。✌️variables: solar_azimuth: "{{ states('sensor.sun_solar_azimuth') | int}}" is_evening: >- {{ ( solar_azimuth >= 0 and solar_azimuth < 90 ) or ( solar_azimuth > 270 and solar_azimuth < 360 )}} light_1_brightness: "{{ ((solar_azimuth - 270)/180) | abs if is_evening else 0 }}" light_2_brightness: "{{ (1 - light_1_brightness) | abs if is_evening else 0 }}" light_3_brightness: "{{ 0 if is_evening else ((solar_azimuth - 90) / 180) | abs}}" light_4_brightness: "{{ 0 if is_evening else (1 - light_3_brightness) | abs }}"
更多好玩的可能性…
还有更多的可玩之处,还没有来得及实验,准备旅行回来试试。比如:
- ❄️ 空调控制:根据入睡时长动态调整温度风速。Sleepal 的温度传感器离你最近,所以也可以代替空调自身的温度传感器,实现更接近体感的空调温控。加湿器同理。
- 💡夜灯模式:起夜离床时,提前打开卫生间夜灯,甚至提前掀开可红外遥控的马桶盖(如 Toto 的 CES802CS),躺床后自动复原,实现更前置灵敏的夜间卫生间整备。
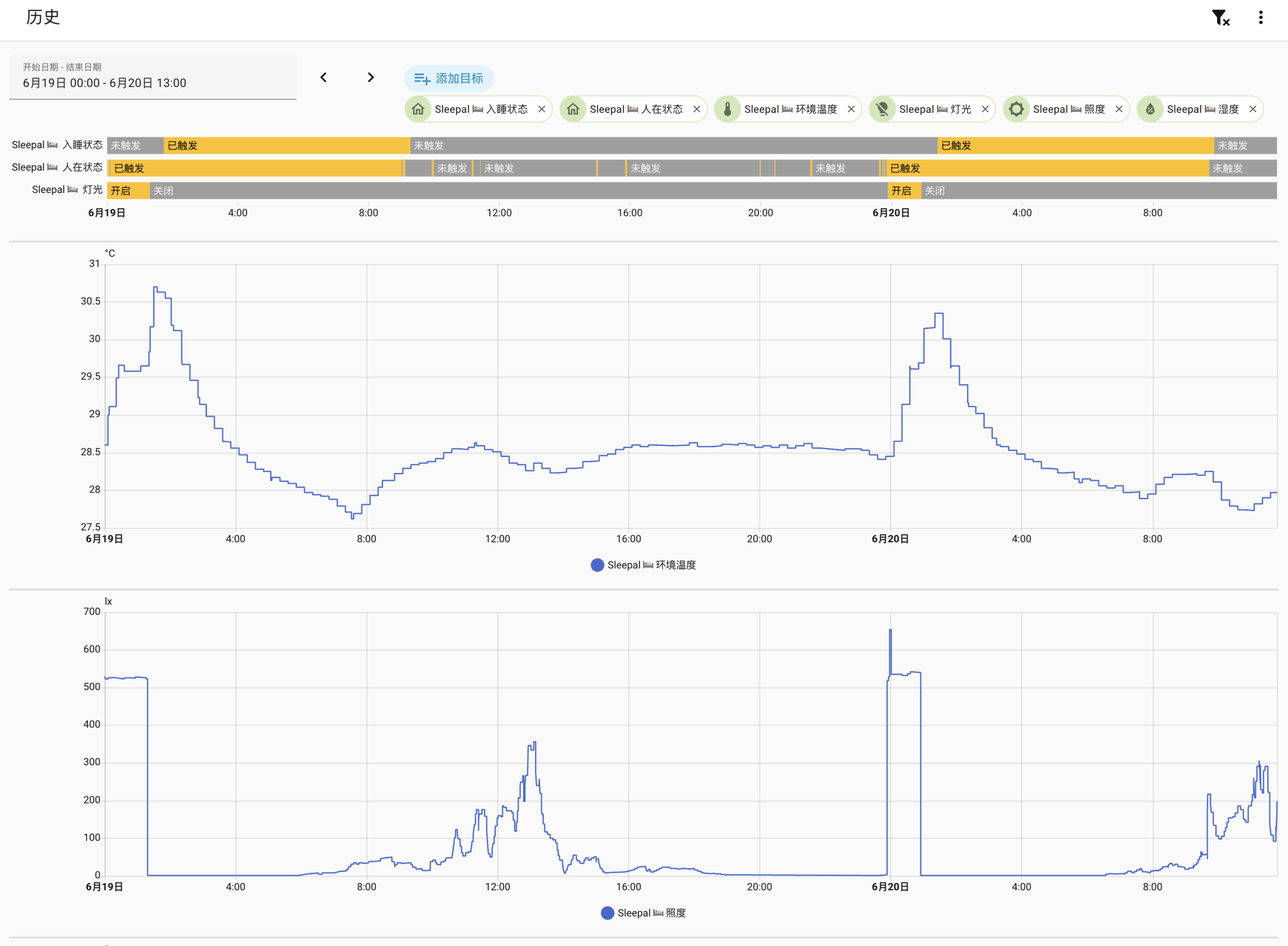
目前的内测版上随着 Matter 接入 HA 的实体有好几个保留项未被定义,不知道未来是否会开放更多。心率呼吸应该是在设备端比较容易,睡眠评分可能是在 app 端生成,不知道是否能够同步 HA。它们能够开放的话,甚至可以通过睡眠质量来进行自动化控制,比如“睡的不好的话,早餐 BGM 自动挑选更轻松的唤醒歌单”。
总之,这是一个非常好玩的产品,也是目前我最能接受的睡眠监测的形态。同时可以带给我很多关于 Home Assistant 控制的新灵感和新思路。产品据说已经开发三年,团队也是「小米人在传感器」的开发者,非常靠谱。目前众筹中,应该可以邮国内,欢迎支持一下范老师哇。